
19
量的研究のすすめ
李 在鎬(り じぇほ)
1.日本語教育との出会い
日本語教育との最初の出会いは、1993年の春のことです。ミュージシャンになることを夢見て、来日した時です。当時は、日本語学習者としてでありました。福島県のいわき市にある小さな大学の留学生別科で日本語を勉強しました。その後、東京の大学で日本語学を勉強し、京都の大学院では理論言語学(認知言語学)の勉強をしました。
大学院を出てからは、複数の研究機関・教育機関で日本語・日本語教育と関わってきました。最初の職場は自然言語処理の研究所でした。いわゆる工学系の言語処理研究者たちに混じって、言語資源構築に関する仕事をしましたが、コンピュータによる自動処理が持つ無限の可能性に感激していたことを今でも覚えています。二番目の職場は、日本語能力試験(Japanese Language Proficiency Test)を作るところでした。目に見えない言語能力を、得点という数値でもって「見える化」する作業に対して、大きな可能性を感じながら仕事をしました。三番目の職場では大規模なeラーニングのシステムを作る仕事をしました。ウェブという限りなく広い大海原に日本語教育の教材を浮かせ、時間と空間を超えて、教育のコンテンツを提供する仕組みにワクワクしながら仕事をしました。そして、今は日本語教育のプロを目指す大学院生たちと切磋琢磨しながら、日本語教育の可能性を広げるための仕事をしています。
私の場合、仕事に関しても、研究に関しても内容面の一貫性はありませんが、方法論面の一貫性はあります。それは、量的研究を意識しながら研究してきたこと、異分野の人との共同研究を重視してきたことです。特に、近年は、コーパスや大規模なテキストデータを統計的に処理した仮説検証型の研究でもって、日本語教育に貢献する方向を模索しています。例えば、文章の難易度を自動判別する方法を開発しました。(「jReadability日本語文章難易度判別システム:http://jreadability.net/」)。
2.量的研究とは
ところで、皆さんは、量的研究と聞くと何を想像しますか。数値や数式がたくさん出てくる研究ですか。コンピュータをかつかつと動かして処理をしていく研究ですか。統計モデルの話が出てくる研究ですか。イメージは色々だろうと思いますが、「実証的」「客観的」「理系的」といった修飾句を想起される方が多いのではないでしょうか。そして、質的研究に対立する研究法として捉えられ、人文系の研究としてはあまり一般的ではないと考える人も少なくないかもしれません。
個人的には、量的研究と質的研究は、車の両輪のようなもので、日本語教育学の発展のためには、両者がうまく連動していくことが不可欠だと考えています。この前提のもとで、量的研究を位置づけた場合、結局のところ、量的研究も質的研究も「データをどう表現するかのバリエーション」ということに帰着すると考えています。例えば、日本語学習者に語彙テストをし、テスト後にフォローアップインタビューをしたとします。学習者の回答行動をテスト得点の面からアプローチし、数値の分布として議論した場合は、量的分析になりますが、回答の正誤の原因などを語彙難易度の面から議論した場合は、質的な分析になります。量的分析にせよ、質的分析にせよ、学習者のテストにおける回答行動を示した「(行動の)データ」という意味では同じなわけです。さらには、フォローアップインタビューについても、発話内容を文字化し、それを自然言語処理の解析ツールで機械的に処理し、1文の長さや語種の比率や単語の使用率の面から表現した場合、量的分析になりますが、分析者が(学習者の)発言間を関連づけながら学習ストラテジーを探る分析を行った場合は質的分析になります。つまり、量的分析と質的分析は、自分の研究対象(研究データ)を数値に変換するのか、記号列に変換するのかの違いでしかないと考えています。
3.「共通言語」としての量的研究
量的研究が共通して用いる数値や統計処理は、分野を超えた「共通言語」になると考えています。どういうことでしょうか。
神吉宇一(編)(2015)『日本語教育 学のデザイン』に収録されている神吉氏の論考の中に、次のようなエピソードが紹介されていました。経済連携協力(EPA)により来日した看護師・介護師候補生の皆さんにとって国家試験が難しすぎるという問題を受け、ルビをつけることになったそうです。それを受け、EPAの担当者は日本語教育の専門家にヒアリングを行ったところ、ある専門家はルビがあったほうが良いと言い、ある専門家はないほうが良いと言ったそうで、結果的には現場の担当者たちを困らせてしまったそうです。神吉氏はこうした問題の根本原因として、主張の根拠となるデータが存在しない、という問題を指摘しています。
日本語教育分野では、伝統的に「経験」が教育や研究の質を決めるという暗黙知があるように思います。「経験」によって培われた「教師の勘」たるものが重視されてきたように思います。私は、「勘」の重要性を否定するつもりはありませんが、しかし、「勘」というのは非常に狭いコミュニティーにおいてしか通じないものです。
近年、日本語教育は非常に多様化してきており、教師の仕事も多様化してきました。これに伴って、日本語教育研究においても他分野の知見を応用することや彼らとの協同作業が不可欠な要素になりつつあります。こうした状況では、「経験」や「勘」よりも、「データ」が重要になります。そして、そのデータを表現する方法として、単に文字を羅列していくやり方ではなく、頻度や数量という観点からデータをとらえることのメリットは非常に大きいです。

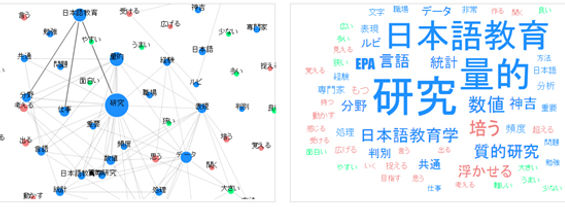
上の図は、この原稿をテキストマイニングの分析ツールで解析したものです。左側の図は、共起ネットワークという手法で、語の出現頻度や(語と語の)共起度を統計的に処理し、丸と線による2次元の図で表したものです。右側の図は、ワードクラウドという手法で、使用頻度と品詞を文字の大きさと色で表現したものです。
「経験」によって培われた「勘」でもって、言語データを質的に分析していく方法ももちろん重要ですし、必要なことです。しかし、文字を数値に変換し、数値を統計的な方法でもって分析することによって、いつだれが分析しても同じ結果になり、どの分野の人にとっても理解しやすい形で自分のデータを表現できます。これこそが量的研究が持つ「共通言語」としての強みであり、最大の魅力と言えます。
あなたも量的研究をすすめることで、もっともっと日本語教育学の面白さを、他分野の人に伝えてみませんか。
《プロフィール》
早稲田大学大学院日本語教育研究科准教授
京都大学人間環境学研究科博士課程修了。博士(人間環境学)。
2014年日本語教育学会奨励賞受賞。
研究および主要業績は、http://jhlee.sakura.ne.jp/page5.html 参照